
ETL (Extract, Transform, and Load) has been a part of just about every digital transformation project we have worked on at Ronin. Whether it’s moving data out of an on-premise legacy system to be consumed by newer cloud-based applications or just combining data from disparate systems to be used in a reporting data warehouse, ETL processes are a necessary part of most enterprise solutions. So, what does Azure provide to help us with ETL?
Revising Our Approach
For a few years, the approach we used was relatively bare metal. That is, we leveraged Azure Functions and Web Jobs to connect to data sources, transform the data with custom code, and ultimately push it to a target location. It got the job done for sure, but as you can imagine there is fair amount of boiler plate code. Additionally, the monitoring and scaling implementations were different for each solution.
Today, every ETL discussion starts with Azure Data Factory. While we had to pass on using early versions of ADF in favor of the bare metal process to really get our work done, that’s not the case anymore. ADF has a ton of ways to ingest data, it scales well, and Data Flow offers a ton of transformation options without writing any custom code.
Our High-Level Decision Guide
Microsoft positions ADF specifically as an Azure service to manage ETL and other integrations at big data scale. While there are many ways to employ ADF for the solution, we’ve specifically found the following questions and answers most useful as our guide:
- If we only need to perform extraction and loading of data (for example making data from a legacy system available in the cloud), ADF’s basic pipeline activities are sufficient.
- If we also need transformations, we’ll start out using ADF’s Data Flow features. We have found that the majority of transformations that we need (joins, unions, derivations, pivots, aggregates, etc) can be handled with the Data Flow user interface.
- If the transformations involve some edge case scenarios, are hard to visualize in a UI, or there is just a comfort level developing it as code, Azure Databricks (ADB) integration can be used to perform these transformation.
Basic Pipeline Activities Approach
The basic workflow in an Azure Data Factory is called a pipeline. A pipeline is an organization of activities (data movement, row iteration, conditionals, basic filtering, etc) against source and target data sets. Directly, it offers little in the way of transformation activities, though you can hook it to Azure Functions or Azure Databricks (see Azure Databricks Approach below) for more advanced cases.
Below is an example basic pipeline I created very quickly using just a few standard activities. This pipeline simply reads an Employee CSV dataset from Azure BLOB storage, filters the records to only those of new employees, then loops over each row and calls a stored procedure to insert each employee record into a SQL Server database table. The resulting output in the bottom frame is from a debug session.
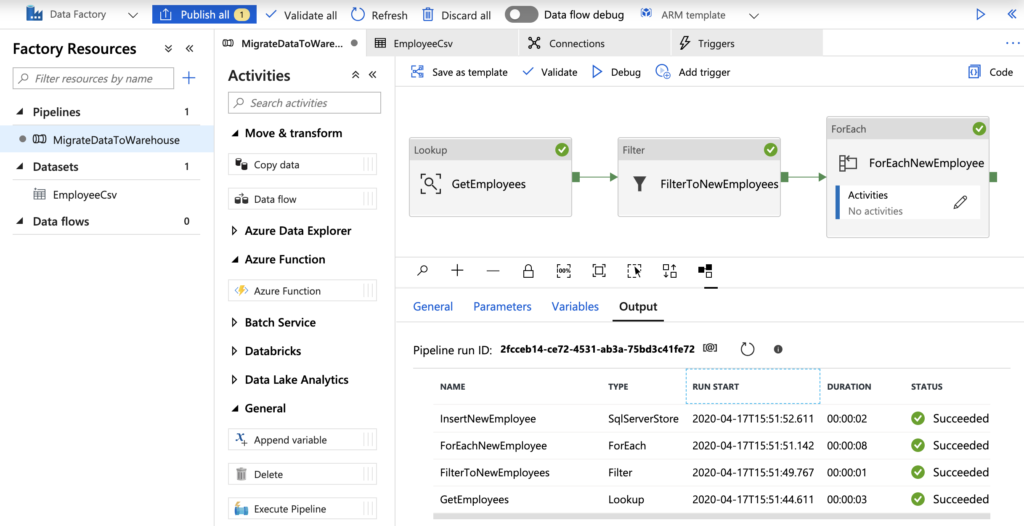
For more information on pipelines and available activities, check out https://docs.microsoft.com/en-us/azure/data-factory/concepts-pipelines-activities.
Data Flow Approach
A Data Flow is a visually designed data transformation for use in Azure Data Factory. The Data Flow is designed in ADF, then invoked during a pipeline using a Data Flow Activity. The transformations offered here offer a lot of power and configuration options through an easy to follow interface. Joining and splitting data sets, cleaning data, deriving new columns, filtering and sorting results, and running expression functions on row data are some of the possibilities with Data Flow. All of it is done through simple user interface controls.
Below is an example mapping data flow I created to show just a few of the transformation components that can be used. of the very quickly. This data flow reads HR employee data, contractor data, and billing info from three different systems. It performs some filtering and new column generation, then combines all of these results. Finally, it sorts the results and drops it to a CSV file.
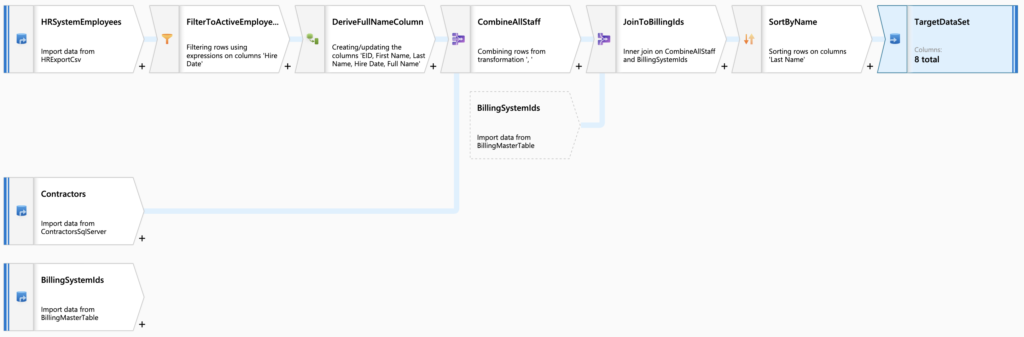
For more information on Data Flows, check out https://docs.microsoft.com/en-us/azure/data-factory/concepts-data-flow-overview.
Azure Databricks Approach
There are times when it makes sense to simply write code to perform a data transformation. For example:
- There’s a weird edge case that the data flow user interface can’t accommodate.
- There’s going to be a high degree of refactoring (change) needed over time and the data flows will be large. It would be much easier / faster to tweak the code than to try to re-write large data flows.
- The source data is already exported as enormous amounts of unstructured data into Azure Data Lakes Storage, the file system natively integrated into Azure Databricks.
In these cases, Azure Data Factory pipelines can invoke notebooks in Azure Databricks using a Databricks Notebook activity. Notebooks define Scala, Python, SQL, or Java code to manipulate and query large volumes of data (terabytes) on its specialized Azure Data Lake Storage file system.
In the below example, I created a simple Databricks notebook to read two CSV files that have been dropped into Azure Data Lake Storage. These could have just as easily been Excel, JSON, parquet, or some other file format as long as there is an extension to read them into data frames. This example takes employee and HR files, joins the rows, computes a PTO Remaining column, orders the results, then stores the data back out as a new CSV file. Azure Data Factory would have a pipeline configured with a Databricks Notebook activity to call this notebook, passing the two CSV file names.
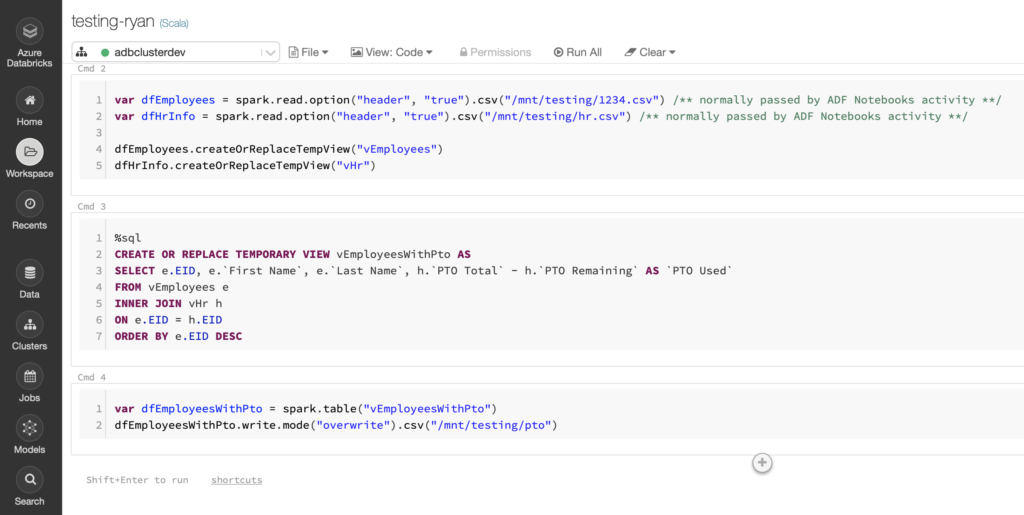
Note how you can seamlessly switch between languages in a notebook. This one is a Scala based notebook that switches to SQL midway through. The environment is also very interactive for debugging against large amounts of data, a nice feature since the ADF user interface can only show limited amounts of data in its debug sessions.
Interestingly, ADF’s data flows are implemented as generated Scala code running in its own managed Databricks cluster. This all happens behind the scenes, but it explains why it’s actually hard to come up with everyday use cases where data flows aren’t sufficient. For more information on transformations with ADB, check out https://docs.microsoft.com/en-us/azure/azure-databricks/databricks-extract-load-sql-data-warehouse.
Parting Thoughts
As awesome as ADF is, it is true that it’s not always the be-all and end-all for ETL. There are still times when ADF is only part of the solution. For example:
- The server infrastructure hosting an on-premise or alternate cloud database from which ADF needs to pull can’t host the integration runtime (a requirement for ADF to reach the data). In this case, we may have to design and build interesting ways to get the data out and into Azure, accessible to ADF
- Though accessible by network to ADF, the source data is contained in a format ADF can’t read. In this case, we may have to build or leverage 3rd party software to extract the data into a digestible format for ADF
- The source data’s schema is so bonkers, Azure Databricks is necessary to pull off the transformation. However, the client may be unwilling to pay the heft ongoing cost of ADB, or they may not be comfortable supporting it down the road and would rather see a more traditional C# or T-SQL coded solution. In this case, we may fall back to a bare metal approach.
Like most software projects, one-size never fits all. But we highly recommend you give ADF a strong look on your next ETL adventure. We’d love to help you with it!
About Rōnin Consulting – Rōnin Consulting provides software engineering and systems integration services for healthcare, financial services, distribution, technology, and other business lines. Services include custom software development and architecture, cloud and hybrid implementations, business analysis, data analysis, and project management for a range of clients from the Fortune 500 to rapidly evolving startups. For more information, please contact us today.




